Can generative AI meaningfully contribute to a mature, widely-used library like NumPy? During my three-month internship as a POSSEE intern, I had an opportunity to explore that very question. Our pod was tasked with investigating how Generative AI could help maintain NumPy repositories by generating useful pull requests (PRs). This blog post outlines the objectives assigned, which centered on improving documentation, test coverage, and resolving bugs, the tools we built, and the contributions we made.
"NumPy is the fundamental package for scientific computing in Python. It is a Python library that provides a multidimensional array object, various derived objects (such as masked arrays and matrices), and an assortment of routines for fast operations on arrays, including mathematical, logical, shape manipulation, sorting, selecting, I/O, discrete Fourier transforms, basic linear algebra, basic statistical operations, random simulation and much more."
"Generative AI refers to a type of artificial intelligence that focuses on creating new content, such as code, images or even text, rather than simply analyzing or classifying existing data. It utilizes machine learning models to learn the underlying patterns and structures within a dataset and then generate novel outputs that resemble the training data."
"Prompt engineering is the art and science of designing and optimizing prompts to guide AI models, particularly LLMs, towards generating the desired responses."
We began this project by targeting several critical areas for improvement through AI-assisted tools. Specifically, we set out to create a docstring_analyzer, a test coverage enhancer, an issue resolution tool, and a PR review tool. These tools were to be designed to automate time-consuming tasks, freeing up NumPy maintainers to concentrate on more strategic work. In this blog I will focus on the tools we used to address the need to identify the functions and methods without docstrings and consequently generating and injecting them into the NumPy codebase.
To ensure effective contributions to the project, we spent the first month getting familiar with the NumPy codebase and the GitHub workflow. My first pull request: [DOC: Adding links to polynomial table. #26442] added links to the polynomial classes table to improve readability.
The first step was identifying functions and methods without docstrings. Leveraging chatGPT, docstring_analyze tool was engineered. This tool recursively searches the NumPy codebase, specifically .py files, and generates a CSV file containing comprehensive function metadata. The tool’s modular design enables customization, allowing for the extraction of varied information and the analysis of different file types. This initial step was essential for preparing the codebase for AI-assisted docstring generation.
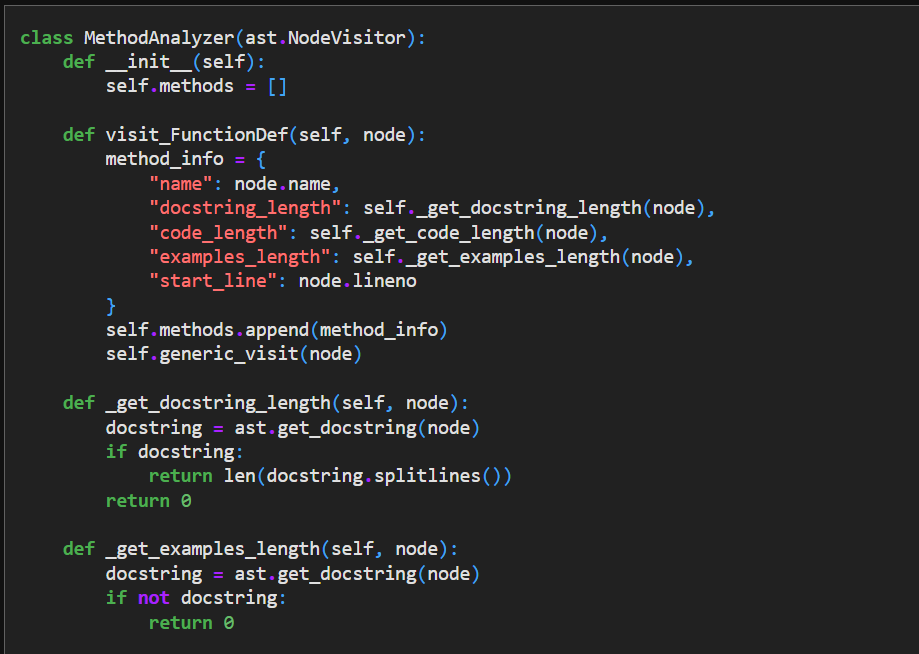
This is an extract of the docstring_analysis.ipynb file designed to analyze methods (functions) in the Numpy codebase. It extracts and records various attributes of each method, such as its name, the length of its docstring, and the start line number.
Reference: GPT4 used to help create docstring_analysis.ipynb. co-authored by Ben Woodruff
The next step involved coming up with a prompt creator tool that creates a prompt that you can pass into an LLM which includes several examples of function code and corresponding docstrings from a given file followed by code for a function that we wish to predict docstrings for.
Sample Output for the tensorsolve Function
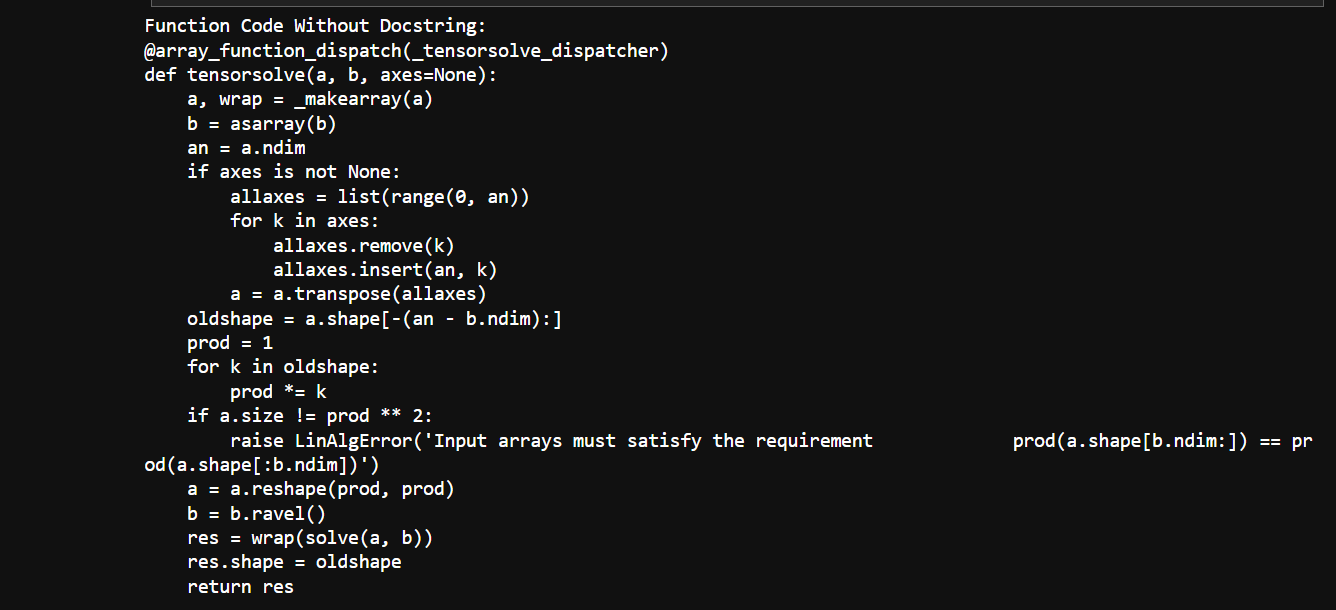
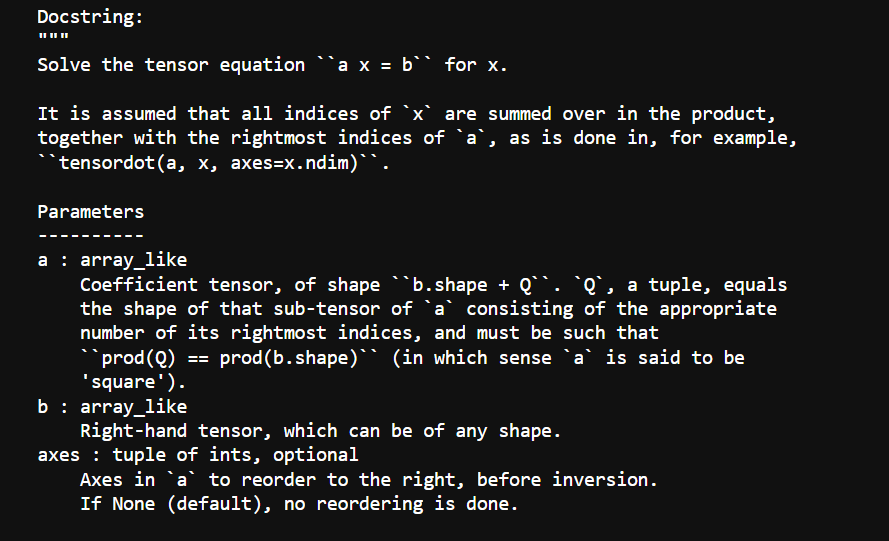
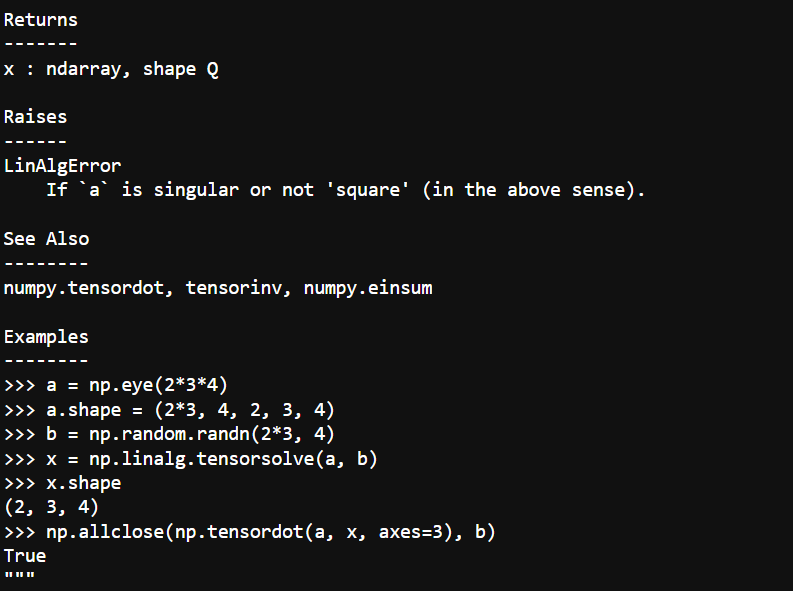
Reference: Script that creates a prompt that passes into an LLM example-generator.py
We observed that using Llama3-8B to generate the docstrings examples resulted in too many repetitive examples that were of very low quality even though the example generation was fast. Using Llama3-70B on the other hand created better examples with minimal duplication which were removed manually.
To streamline integration, we built example_post_processing.py to insert generated examples into the codebase. While the generated code generally executes, we encountered challenges with hallucinated outputs, which were resolved by replacing them with actual results. Additionally, issues with special characters and verbatim copying were mitigated using the fuzzywuzzy package for line identification.
For future iterations, we aim to refine prompt formats to further improve accuracy and reduce editing.
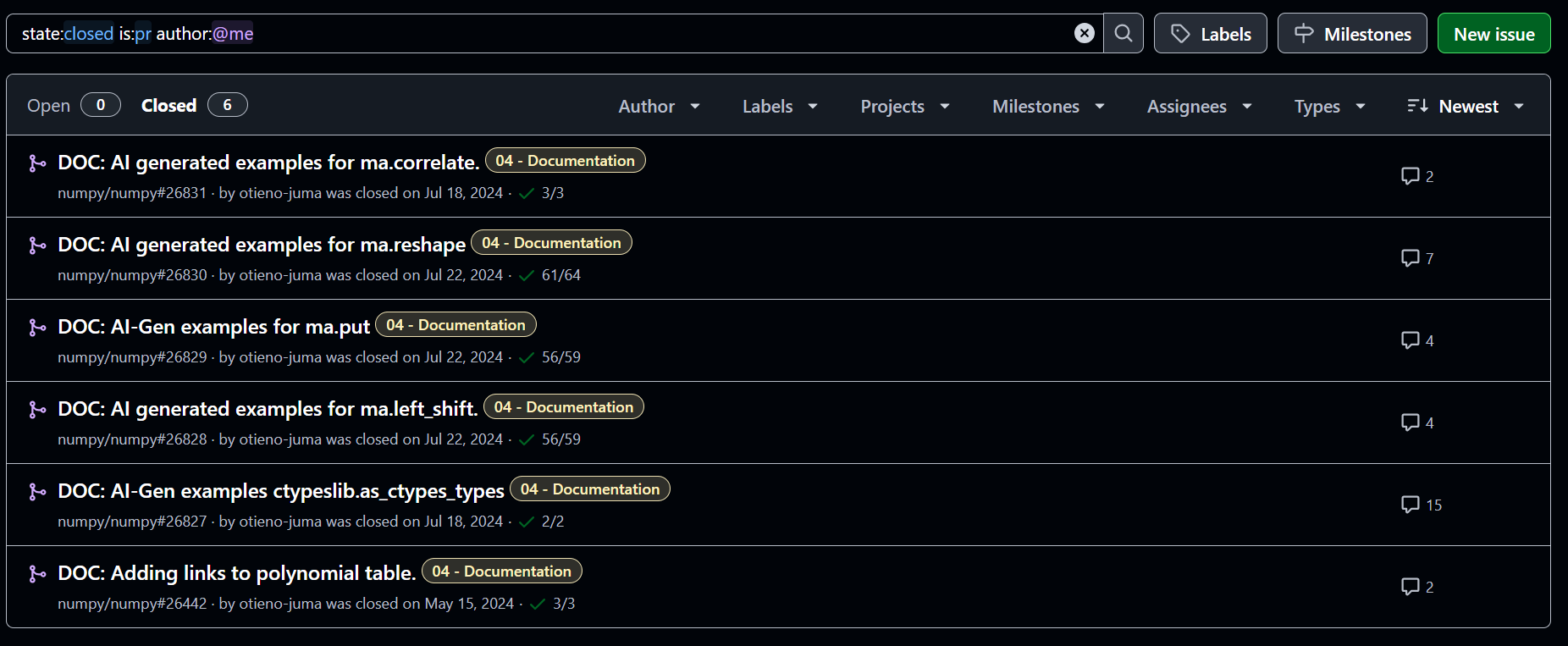
Below are Pull requests(PRs) merged into the NumPy repository:
The integration of generative AI into open-source workflows, especially for documentation, represents a promising new direction. While some skepticism is healthy, this project demonstrates that with thoughtful human oversight and strong QA processes, Generative AI can:
We hope more open-source communities will explore and experiment with Generative AI tools responsibly and collaboratively, building upon successes like this one to shape a future where GenAI serves as a valuable partner in the evolution of open-source software.
This project would not have been possible without the support and dedication of a fantastic team. I want to especially thank Ben Woodruff for his expert technical guidance and Inessa Pawson for her exceptional program management and mentorship skills. My heartfelt gratitude also goes to George Ogidi and Ebigide Jude for their hard work and collaborative spirit, which significantly contributed to the project’s achievements. Finally, I’m deeply grateful to the POSSEE program and its partners for investing in projects like this. As a direct beneficiary of their extensive support network, including student mentors and career coaches, I’ve experienced firsthand the program’s value and has been instrumental in my career growth. I hope these opportunities continue to be extended to BYU Pathway students and learners worldwide, contributing to a growing and inclusive open-source community.
POSSEE promotes equitable education and open source sustainability, fostering technological and social progress across the globe.